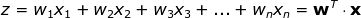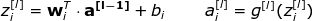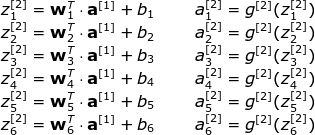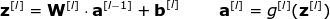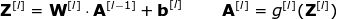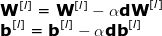新智元推荐 来源:AI科技大本营(ID:rgznai100) 作者:Piotr Skalski
译者:巧克力 编辑:Jane
【新智元导读】为了更好地理解神经网络的运作,今天只为大家解读神经网络背后的数学原理。而作者写这篇文章的目的一是为了整理自己学到的知识;二是希望这篇文章可以有助于大家的学习与理解。对于代数和微积分相关内容基础薄弱的小伙伴们,虽然文中涉及不少数学知识,但我会尽量让内容易于理解。
解析深度网络背后的数学
如今,已有许多像 Keras, TensorFlow, PyTorch 这样高水平的专门的库和框架,我们就不用总担心矩阵的权重太多,或是对使用的激活函数求导时存储计算的规模太大这些问题了。基于这些框架,我们在构建一个神经网络时,甚至是一个有着非常复杂的结构的网络时,也仅需少量的输入和代码就足够了,极大地提高了效率。无论如何,神经网络背后的原理方法对于像架构选择、超参数调整或者优化这样的任务有着很大的帮助。
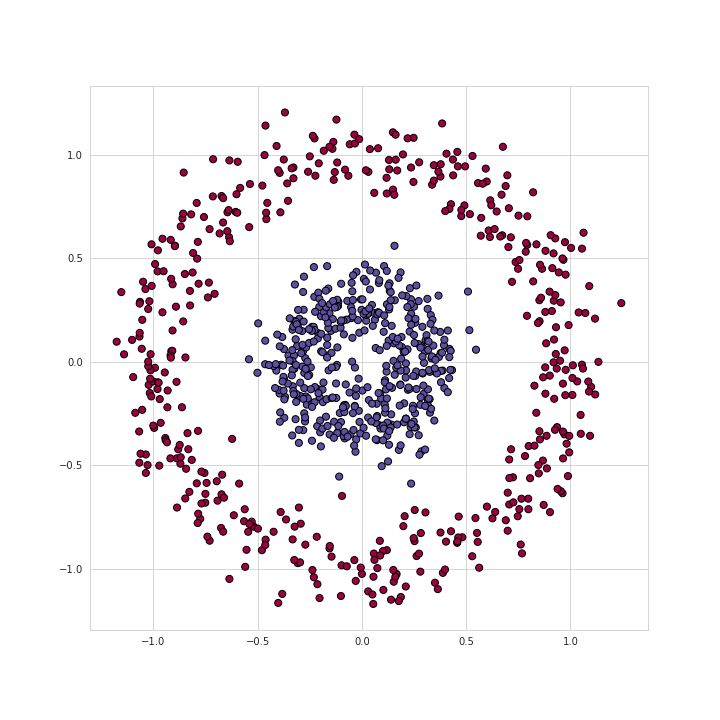
图一 训练集可视化
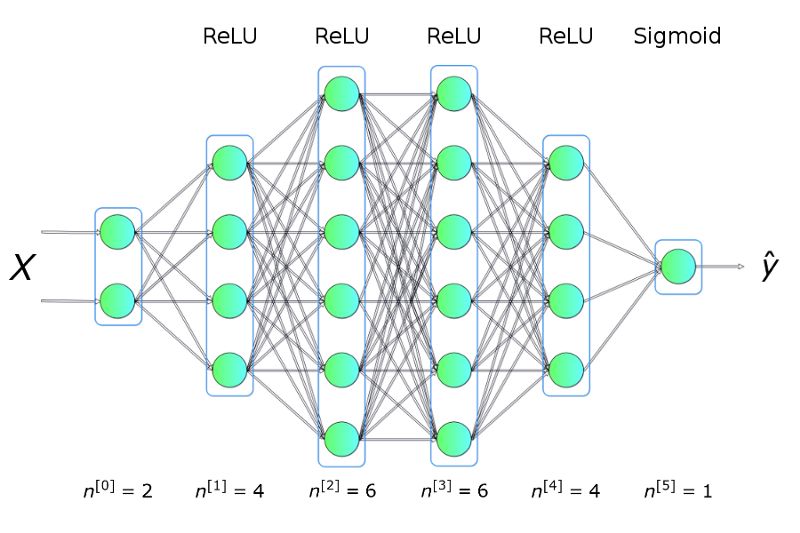
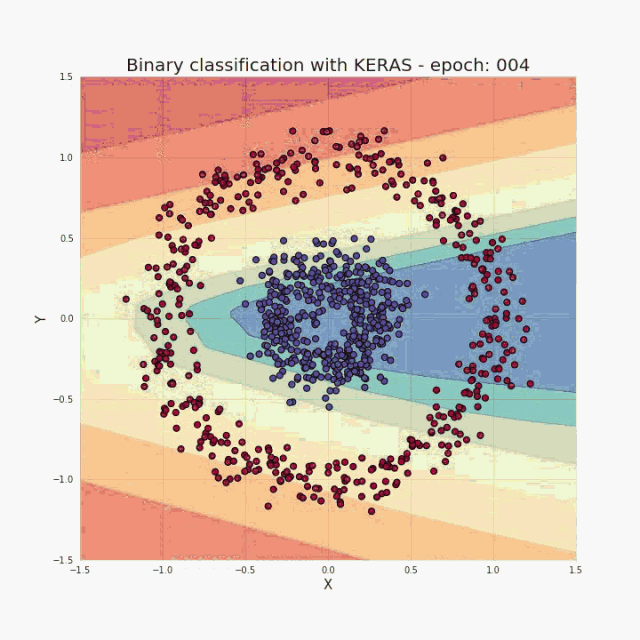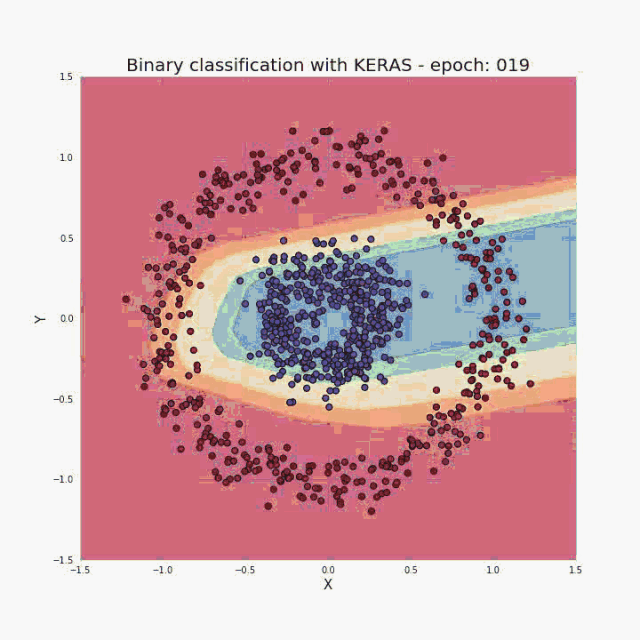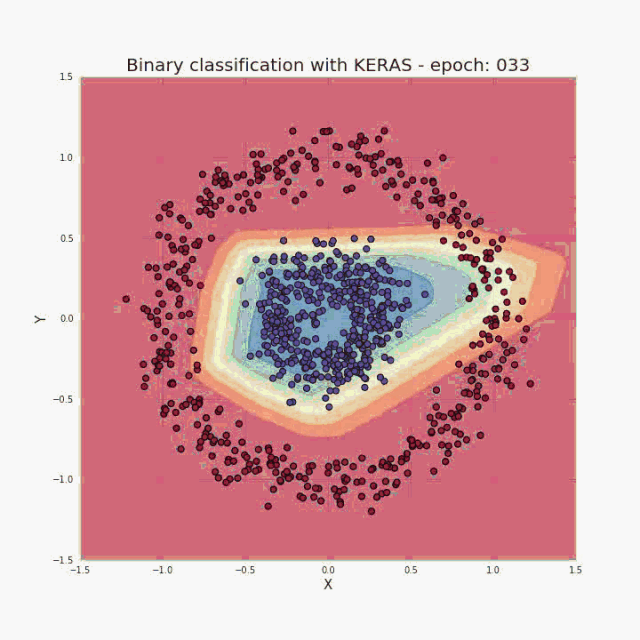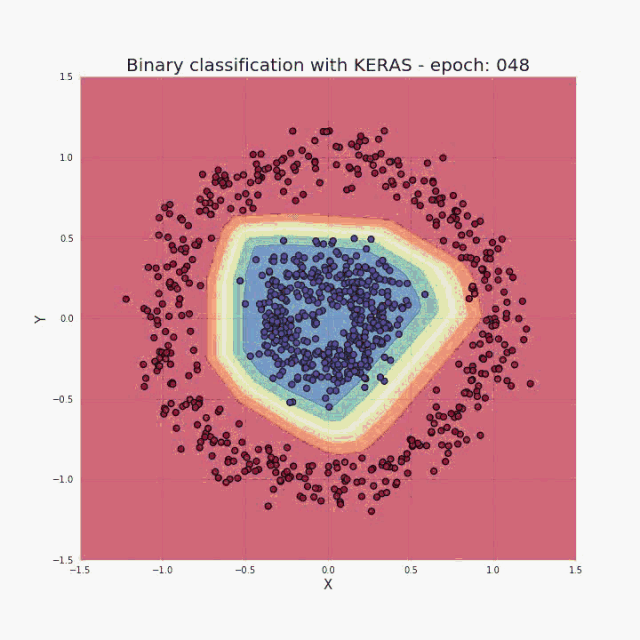
举个例子,我们将利用上图展示的训练集数据去解决一个二分类问题。从上面的图可以看出,数据点形成了两个圆,这对于许多传统的机器学习算法是不容易的,但是现在用一个小的神经网络就可能很好地解决这个问题了。为了解决这个问题,我们将构建一个神经网络:包括五个全连接层,每层都含有不同数目的单元,结构如下:
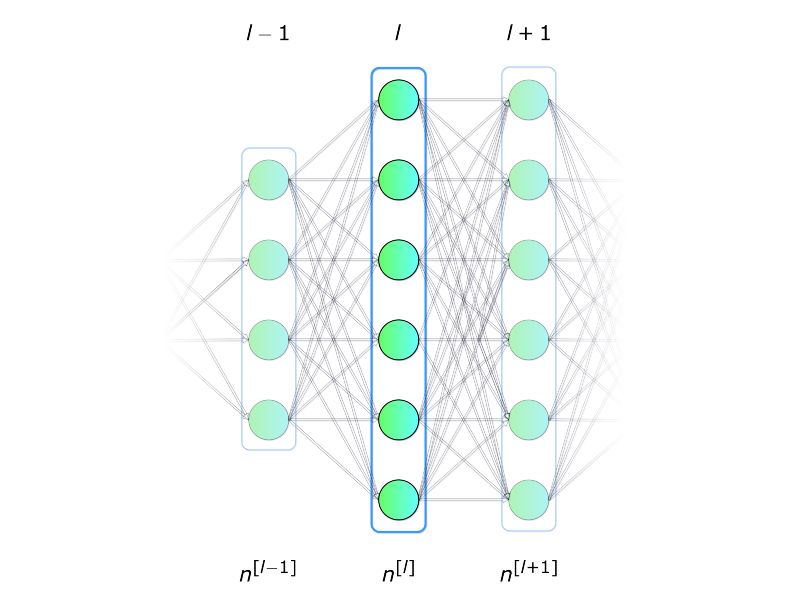
图二 神经网络架构
其中,隐藏层使用 ReLU 作为激活函数,输出层使用 Sigmoid。这是一个非常简单的架构,但是对于解决并解释这个问题已经足够了。
用 KERAS 求解
首先,先给大家介绍一个解决方法,使用了一个最受欢迎的机器学习库—— KERAS 。
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(4, input_dim=2,activation='relu'))
model.add(Dense(6, activation='relu'))
model.add(Dense(6, activation='relu'))
model.add(Dense(4, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=50, verbose=0)
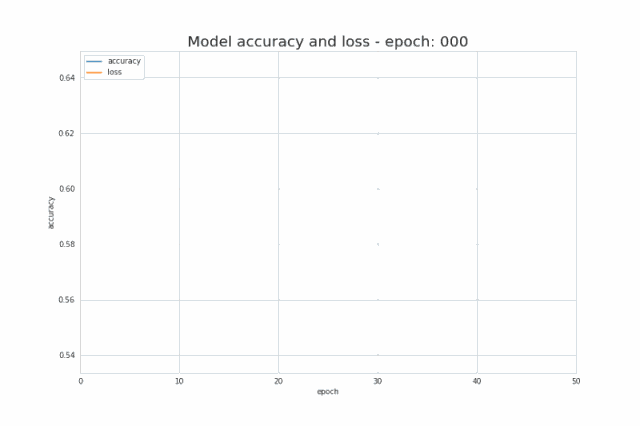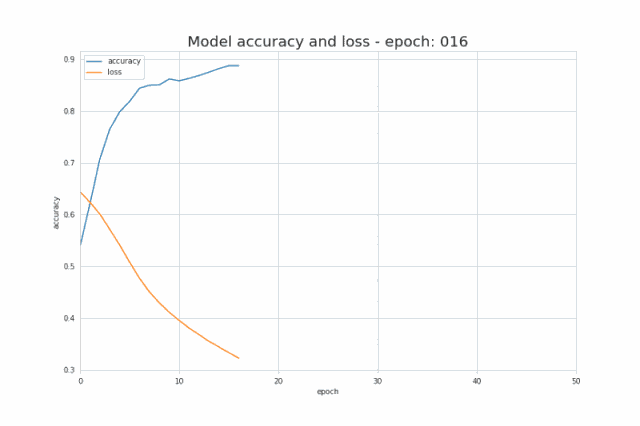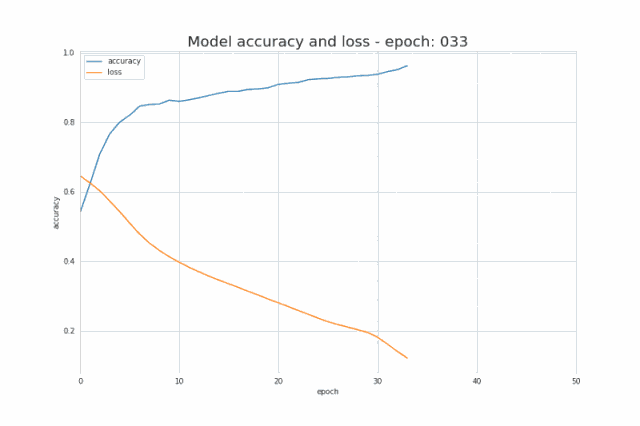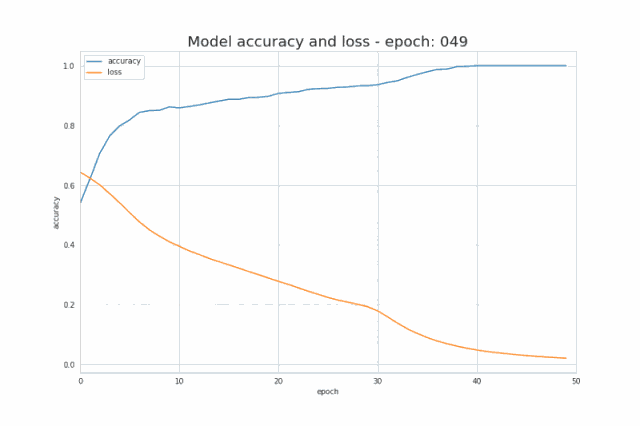
正如我在简介中提到的,少量的输入数据和代码就足以构建和训练出一个模型,并且在测试集上的分类精度几乎达到 100%。概括来讲,我们的任务其实就是提供与所选架构一致的超参数(层数、每层的神经元数、激活函数或者迭代次数)。先给大家展示一个超酷的可视化结果,是我在训练过程中得到的:  图三 训练中正确分类区域的可视化
现在我们来解析这背后的原理。
什么是神经网络?
让我们从关键问题开始:什么是神经网络?它是一种由生物启发的,用来构建可以学习并且独立解释数据中联系的计算机程序的方法。如上图二所示,网络就是各层神经元的集合,这些神经元排列成列,并且相互之间连接,可以进行交流。
单个神经元
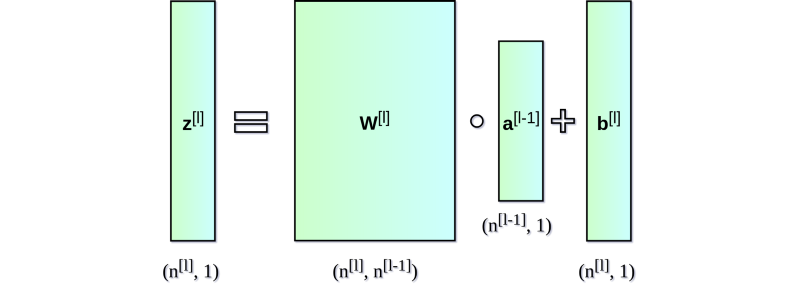
每个神经元以一组 x 变量(取值从 1 到 n )的值作为输入,计算预测的 y-hat 值。假设训练集中含有 m 个样本,则向量 x 表示其中一个样本的各个特征的取值。此外,每个单元有自己的参数集需要学习,包括权重向量和偏差,分别用 w 和 b 表示。在每次迭代中,神经元基于本轮的权重向量计算向量 x 的加权平均值,再加上偏差。最后,将计算结果代入一个非线性激活函数 g。我会在下文中介绍一些最流行的激活函数。
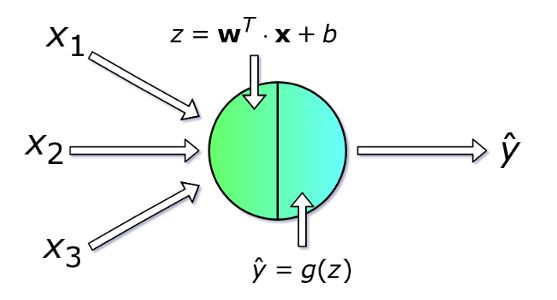
 图四 单个神经元
单层
现在我们看一下神经网络中整体的一层是怎么计算的。我们将整合每个单元中的计算,进行向量化,然后写成矩阵的形式。为了统一符号,我们选取第 l 层写出矩阵等式,下标 i 表示第 i 个神经元。
图五 单层神经网络
注意一点:当我们对单个单元写方程的时候,用到了 x 和 y-hat,它们分别表示特征列向量和预测值。但当我们对整个层写的时候,要用向量 a 表示相应层的激活值。因此, 向量 x 可以看做第 0 层输入层的激活值。每层的各个神经元相似地满足如下等式:
为了清楚起见,以下是第二层的所有表达式:
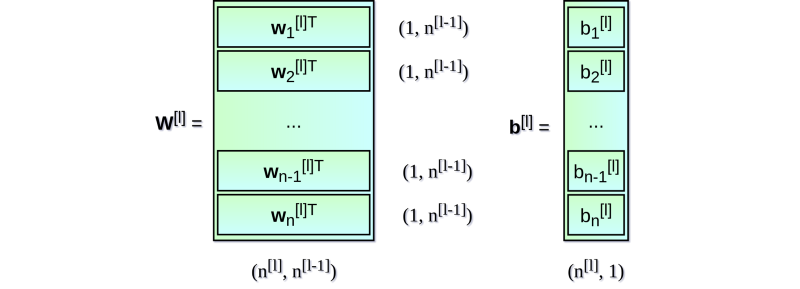
可见,每层的表达式都是相似的。用 for 循环来表示很低效,因此为了加速计算速度我们使用了向量化。首先,将权重向量 w 的转置堆叠成矩阵 W。相似地,将各个神经元的偏差也堆在一起组成列向量 b。由此,我们就可以很轻松地写出一个矩阵等式来表示关于某一层的所有神经元的计算。使用的矩阵和向量维数表示如下:
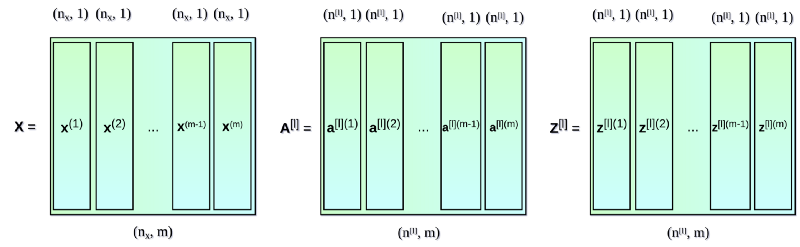
多样本向量化
到目前为止,我们写出的等式仅包含一个样本。但在神经网络的学习过程中,通常会处理一个庞大的数据集,可达百万级的输入。因此,下一步需要进行多样本向量化。我们假设数据集中含有 m 个输入,每个输入有 nx 个特征。首先,将每层的列向量 x, a, z 分别堆成矩阵 X, A, Z。然后,根据新的矩阵重写之前的等式。
 
什么是激活函数?我们为什么需要它?
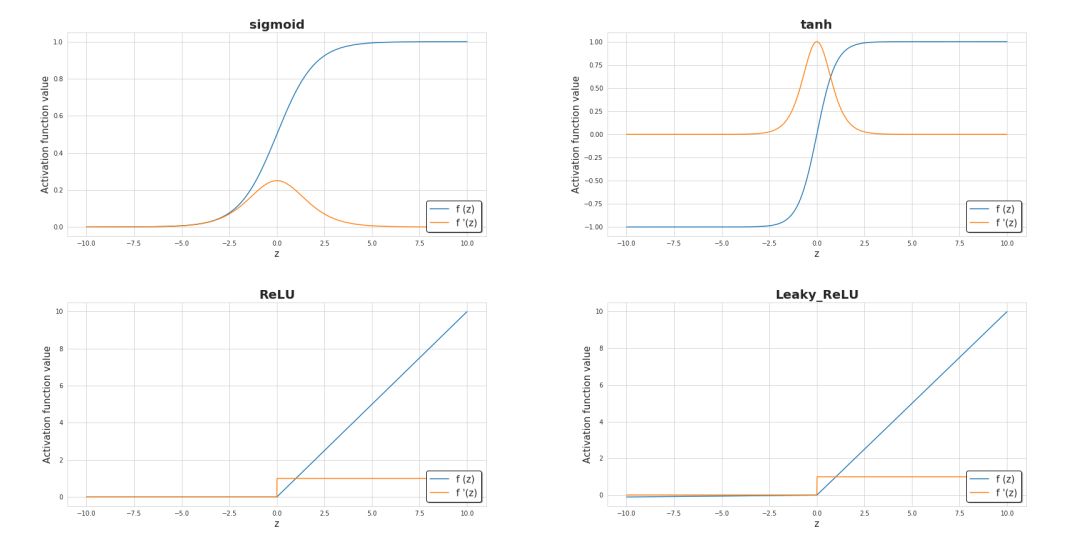
激活函数是神经网络的关键元素之一。没有它们,神经网络就只是一些线性函数的组合,其本身也只能是一个线性函数。我们的模型有复杂度的限制,不能超过逻辑回归。其中,非线性元保证了更好的适应性,并且能在学习过程中提供一些复杂的函数。激活函数对学习的速度也有显著影响,这也是在选择时的评判标准之一。图六展示了一些常用的激活函数。近年来,隐藏层中使用最广的激活函数大概就是 ReLU 了。不过,当我们在做二进制分类问题时,我们有时仍然用 sigmoid,尤其是在输出层中,我们希望模型返回的值在 0 到 1 之间。
图六 常用激活函数及其导数函数图像
损失函数
关于学习过程进展的基本的信息来源就是损失函数值了。通常来说,损失函数可以表示我们离 “理想” 值还差多远。在本例中,我们用 binary crossentropy(两元交叉熵)来作为损失函数,不过还有其他的损失函数,需要具体问题具体分析。两元交叉熵函数表示如下:

下图展示了在训练过程中其值的变化,可见其值随着迭代次数如何增加与减少,精度如何提高
图七 训练过程中精确度及损失的变化
神经网络如何学习?
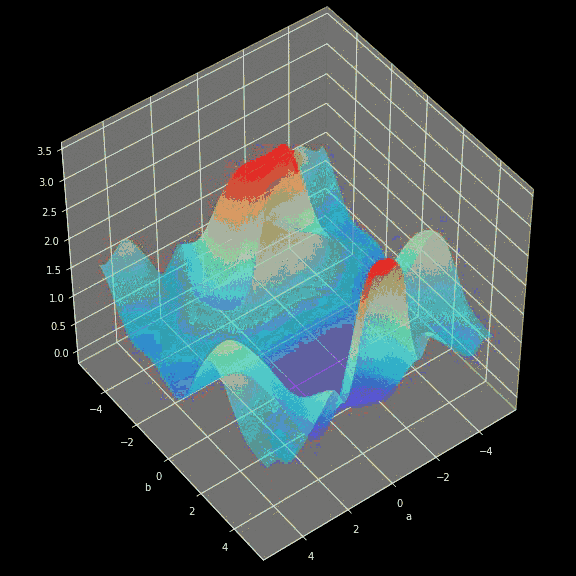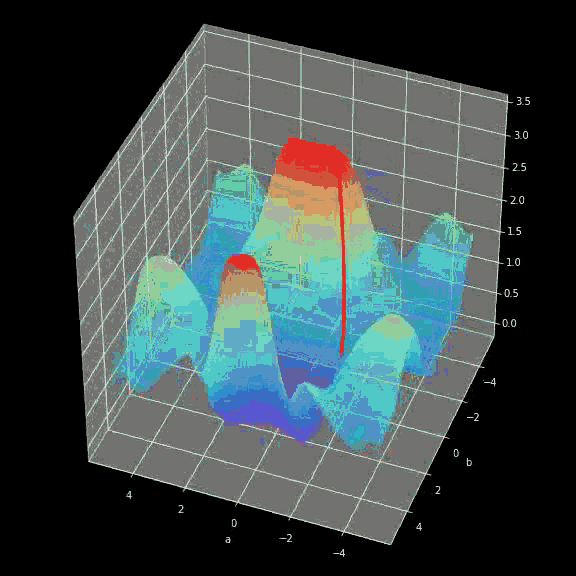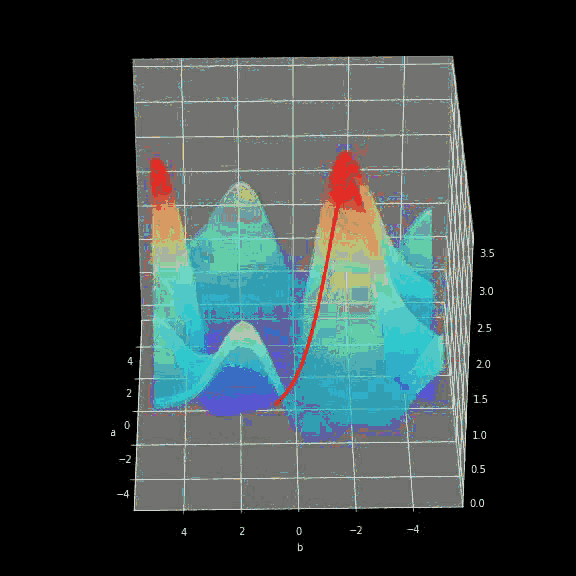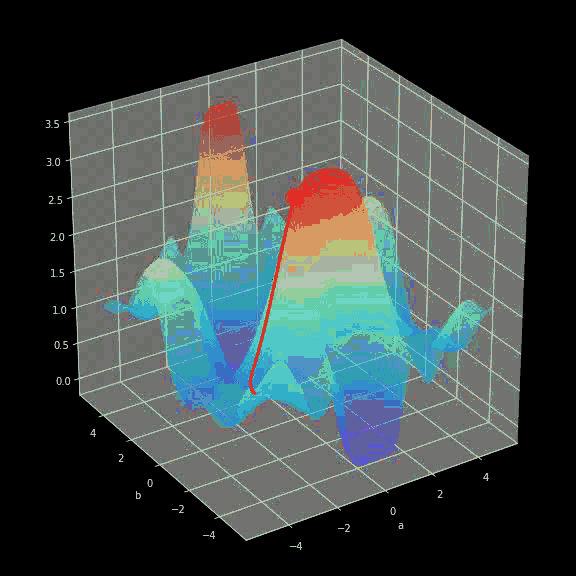
学习过程其实就是在不断地更新参数 W 和 b 的值从而使损失函数最小化。为此,我们运用微积分以及梯度下降的方法来求函数的极小。在每次迭代中,我们将分别计算损失函数对神经网络中的每个参数的偏导数值。对这方面计算不太熟悉的小伙伴,我简单解释一下,导数可以刻画函数的(斜率)。我们已经知道了怎样迭代变量会有怎么样的变化,为了对梯度下降有更直观的认识,我展示了一个可视化动图,从中可以看到我们是怎么通过一步步连续的迭代逼近极小值的。在神经网络中也是一样的——每一轮迭代所计算的梯度显示我们应该移动的方向。而他们间最主要的差别在于,神经网络需要计算更多的参数。确切地说,怎么计算如此复杂的导数呢?
图八 动态梯度下降
反向传播算法
反向传播算法是一种可以计算十分复杂的梯度的算法。在神经网络中,各参数的调整公式如下:

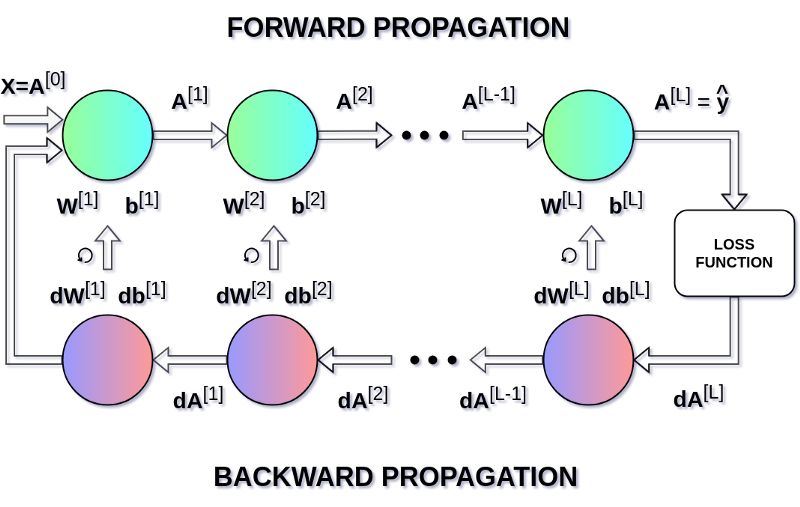
其中,超参数 α 表示学习率,用以控制更新步长。选定学习率是非常重要的——太小,NN 学习得太慢;太大,无法达到极小点。用链式法则计算 dW 和 db —— 损失函数对 W 和 b 的偏导数, dW 和 db 的维数与 W 和 b 相等。图九展示了神经网络中的一系列求导操作,从中可以清楚地看到前向和后向传播是怎样共同优化损失函数的。

图九 前向与后向传播
结论
希望这篇文章对各位小伙伴理解神经网络内部运用的数学原理有所帮助。当我们使用神经网络时,理解这个过程的基本原理是很有帮助的。文中讲述的内容虽然只是冰山一角,但都是我认为最重要的知识点。因此,我强烈建议大家能试着独立地去编一个小的神经网络,不要依赖框架,仅仅只用 Numpy 尝试一下。
原文链接: https://towardsdatascience.com/https-medium-com-piotr-skalski92-deep-dive-into-deep-networks-math-17660bc376ba
| 


 发表于 2018-9-2 16:50:11
发表于 2018-9-2 16:50:11